Once you have installed Observer for ServiceNow, there are a variety of settings you can configure. In Observer, click the menu icon, followed by the Settings (gear) icon. From here, you'll find four tabs: Preferences, Trend Groups, Notifications, and Alert Configurations.
From the Settings page, the Preferences tab allows you to customize the look and feel, as well as the core functionality of Observer.
- Theme: Use the dropdown to change the overall look of Observer. The default theme is set to Dark.
- Credentials: Click Edit to change password(s) for any system user.
Core Functionality: These are advanced configuration settings that require advanced knowledge of Observer. We suggest contacting Perspectium Support before making any changes. Based on the table below, you can change the default values for these attributes by double clicking on the value you want to change, type in the new value, and press Enter.
Attribute Default Value Attribute Description ui.session.timeout30 Indicates the number of minutes that your logged-in session will remain active for. After this number is exceeded, you will automatically be logged out of Observer. email.digest.max500 Indicates a limit for daily digest alert notification emails with repetitive content. Once this limit is reached, a daily digest email will be sent to the email addresses specified in the Notifications tab listing all of the repeat notifications generated by Observer. email.digestenable If enable is entered in the Value column, sends a daily digest (or summary) email to the email addresses specified in the Notifications tab each time the email.digest.maxlimit is reached for repeat Observer notifications. If disable is entered in the Value column, digest emails will be sent to your email address each time Observer posts an alert.ui.perspective.dashboardenable If disable is entered in the Value column, the Dashboard option will not appear in your Observer main menu. ui.perspective.controlenable If disable is entered in the Value column, the Control option will not appear in your Observer main menu. ui.perspective.monitorenable If disable is entered in the Value column, the Monitor option will not appear in your Observer main menu. ui.perspective.trendenable If disable is entered in the Value column, the Trend option will not appear in your Observer main menu. alert.snc.highenable If enable is entered in the Value column, High Alert records will be created in ServiceNow > Control and Configuration > Alerts for each High Alert posted by Observer. alert.snc.mediumenable If enable is entered in the Value column, Medium Alert records will be created in ServiceNow > Control and Configuration > Alerts for each Medium Alert posted by Observer. alert.snc.lowenable If enable is entered in the Value column, Low Alert records will be created in ServiceNow > Control and Configuration > Alerts for each Low Alert posted by Observer. alert.snc.flag.show.all.alwaysdisable If disable is entered in the Value column, only flags that are relevant to the trend group will appear in the trend group chart. If enable is entered in the Value column, then all flags will be available for showing on the trend group chart.
No valid Data Center license found
Please go to Atlassian Marketplace to purchase or evaluate Refined Toolkit for Confluence Data Center.Please read this document to get more information about the newly released Data Center version.
You can create your own custom trend groups. Click +New to create a new group.
To view any custom trend groups, click the arrow button next to Type: Custom, which will reveal any custom trend groups you have created.
To delete a custom trend group, simply click on any group in this custom list, and click Delete Selected.
Click Revert Trend Groups to delete all custom trend groups and revert back to the default groups.
No valid Data Center license found
Please go to Atlassian Marketplace to purchase or evaluate Refined Toolkit for Confluence Data Center.Please read this document to get more information about the newly released Data Center version.
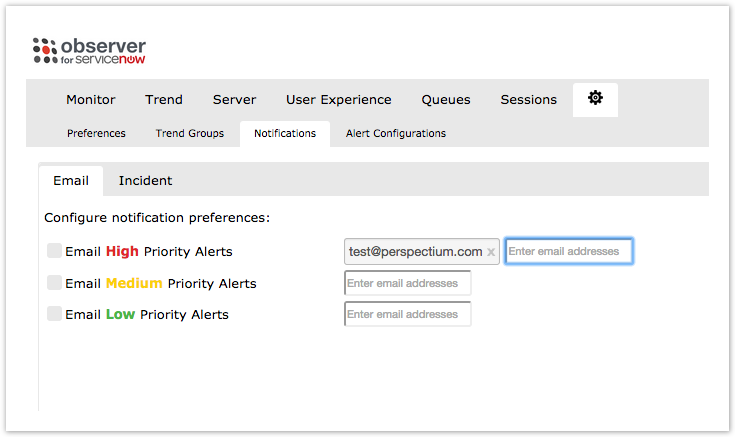
Observer will send out a daily alert email including a breakdown of events for you to view. You can customize the type of notification emails sent out, as well as who receives these emails from the Notification tab of the Settings page.
- Enter any number of emails that you want to receive Observer's daily notification emails - press Enter to add multiple email addresses for each category
- Check the box next to the alert categories you want to receive notification emails for
No valid Data Center license found
Please go to Atlassian Marketplace to purchase or evaluate Refined Toolkit for Confluence Data Center.Please read this document to get more information about the newly released Data Center version.
In addition to the daily notification email, you can receive custom alerts from within Observer. You can adjust the settings for different alert categories. The alert categories and configuration options are described below:
Alert Category | Description |
|---|---|
| High Alert | A high-priority alert on your ServiceNow data |
| Medium Alert | A medium-priority alert on your ServiceNow data |
| Low Alert | A low-priority alert on your ServiceNow data |
Configuration Option | Description |
|---|---|
| Velocity | Indicates a speed limit which, if reached, will trigger alert flags to be posted to trend groups and alert notifications to be emailed to the addresses specified on the Notifications tab, typically expressed as number of SQL statements executed per minute/millisecond |
| Triggering Threshold | Indicates a limit which, if reached, will trigger alert flags to be posted to trend groups and alert notifications to be emailed to the addresses specified on the Notifications tab, typically expressed as number of SQL statements executed |
| Analysis Window | Indicates how frequently Observer should post alert flags to trend groups, typically expressed in minutes |
The default alerts on this tab are organized into the following groups (view more details in the expandable info box below):
- Database
- Errors
- Hardware
- System Queues
- User Experience
Click the arrow icon next to any of the groups to expand and reveal the values. You can select of type the values you want to set for each configuration type.
For example, for the alert Extremely high rate of increase in SQL Response Time, typing 3000 for Triggering Threshold, 1500 for Velocity, and 5 for Analysis Window will trigger alerts to be posted every 5 minutes if 3000+ SQL statements are executed within 1500 milliseconds.
There is also a Description field for each alert configuration in case you want to provide more context on the alert for future reference or other users of your Observer.
To edit or delete an alert's description, right-click in the alert's Description field to open the context menu, where you can update the description and click Save.
For a breakdown of all Observer's built-in default alerts, see the following:
The default alerts are based on metrics collected from your ServiceNow instance. These metrics are sent by your instance to MBS and the specific metrics collected for each alert is described below.
Alert Configuration | Description | Collected Metric |
|---|---|---|
| Out of Semaphores | Each transaction requires a semaphore to begin processing. Extended periods of semaphore unavailability will result in performance degradation and outages | Num free semaphores |
| Excessive browser time | The calculated browser network time is very high | Client browser time |
| Excessive client network time | The calculated client network time is very high | Client network time |
| Excessive server response time | The average server response time has significantly slowed | Server response time |
| Available DB connections exhausted | All database connections are in use, any new transactions will wait for DB availability. This typically indicates a critical problem and usually arises from poor SQL performance | Available DB connections |
| Unable to access instance | The ServiceNow instance is completely unavailable | Log error count |
| Very high rate of increase in errors detected | The error rate suddenly increased | |
| High rate of increase in errors detected | ||
| Extremely slow worker queue | The worker queue processed has significantly degraded | Worker Queue |
| Slow worker queue | ||
| Extremely low app server memory | The ServiceNow application servers are running dangerously low on memory. This typically results from high concurrency and not enough application nodes, a long running transaction requiring a high amount of memory, or a memory leak | Percent free memory of Max |
| Very low app server memory | ||
| Low app server memory | ||
| Stuck Outbound Email Queue | Email is not sending or the queue is growing much faster than it can be depleted. Typically this alert if the job processing email crashes, the SMTP gateway is unavailable, or an abnormally high number of emails were created | Email Queue (send-ready) |
| Unusually high number of ignored inbound emails | A high number of inbound emails are being ignored | Email Queue (received-ignored) |
| Outbound Email Queue fails to send consistently | Email is not sending. Typically this alert if the job processing email crashes, the SMTP gateway is unavailable, or another network problem | Email Queue (send-failed) |
| Excessive number of ECC Queue in processing mode | The ECC queue has a significant number of processing items | ECC Queue (processing) |
| High number of ECC Queue errors | A high number of ECC queue errors occurred | ECC Queue (error) |
| High number of Import Set Run errors | A high number of import set run errors occurred. This may indicate that an import set did not properly execute | Import Set Run Queue (complete_with_errors) |
| High number of Import Sets running | There is a high number of concurrent import sets running that may impact performance | Import Set Run Queue (running) |
| Excessive number of Progress Workers currently running | Excessive number of Progress Workers are running | Progress Worker Queue (running) |
| High number of System Event Queue errors | A high number of system event queue errors occurred | System Event Queue (error) |
| High number of System Event Queue unprocessed | A high number of system event queue items are unprocessed | |
| Extremely high rate of increase in SQL Response Time | The overall SQL performance is degrading at a high rate. This may be an early warning for a database performance bottleneck | SQL response time (1 min) |
| Alarmingly high SQL Response Time | ||
| Very high rate of increase in SQL Response Time | ||
| High rate of increase in SQL Response Time | ||
| Extremely high rate of increase in SQL Inserts | There is a high number of SQL insert statements into the database. This typically will result from an import, integration, or scheduled job that is inserting a large amount of data. This may indicate the beginning of a performance issue | SQL inserts (1 min) |
| Alarmingly high number of SQL Inserts | ||
| Very high rate of increase in SQL Inserts | ||
| High rate of increase in SQL Inserts | ||
| Extremely high rate of increase in SQL Updates | There is a high number of SQL update statements into the database. This typically will result from an import, integration, or scheduled job that is updating a large amount of data. This may indicate the beginning of a performance issue | SQL updates (1 min) |
| Alarmingly high number of SQL Updates | ||
| Very high rate of increase in SQL Updates | ||
| High rate of increase in SQL Updates | ||
| Extremely high rate of increase in SQL Deletes | There is a high number of SQL update statements into the database. This typically will result from an import, integration, or scheduled job that is updating a large amount of data. This may indicate the beginning of a performance issue | SQL deletes (1 min) |
| Alarmingly high number of SQL Deletes | ||
| Very high rate of increase in SQL Deletes | ||
| High rate of increase in SQL Deletes | ||
| Extremely high rate of increase in Active User Sessions | High increases in the rate of Active User Sessions indicate a sudden spike in transaction concurrency by user traffic. This may reflect misconfigurations or security events such as a Denial of Service attack | Active sessions |
| Alarmingly high Active User Sessions | ||
| Very high rate of increase in Active User Sessions | ||
| High rate of increase in Active User Sessions | ||
| Extremely high rate of increase in Logged in User Sessions | A high rate in the number of users are logged into the system. These may be an early indication of a problem or security issue occuring | Logged in sessions |
| Alarmingly high Logged in User Sessions | ||
| Very high rate of increase in Logged in User Sessions | ||
| High rate of increase in Logged in User Sessions | ||
| Extremely high rate of increase in SQL Insert Response Time | The SQL insert performance is rapidly slowing down. This may be an early warning sign of an upcoming performance problem | SQL insert response |
| Alarmingly high number of SQL Insert Response Time | ||
| Very high rate of increase in SQL Insert Response Time | ||
| High rate of increase in SQL Insert Response Time | ||
| Extremely high rate of increase in SQL Update Response Time | The SQL update performance is rapidly slowing down. This may be an early warning sign of an upcoming performance problem | SQL update response |
| Alarmingly high number of SQL Update Response Time | ||
| Very high rate of increase in SQL Update Response Time | ||
| High rate of increase in SQL Update Response Time | ||
| Extremely high rate of increase in SQL Delete Response Time | The SQL delete performance is rapidly slowing down. This may be an early warning sign of an upcoming performance problem | SQL delete response |
| Alarmingly high number of SQL Delete Response Time | ||
| Very high rate of increase in SQL Delete Response Time | ||
| High rate of increase in SQL Delete Response Time |
No valid Data Center license found
Please go to Atlassian Marketplace to purchase or evaluate Refined Toolkit for Confluence Data Center.Please read this document to get more information about the newly released Data Center version.
You can also configure alerts based on Client Browser and Network Time:
You can view the Client Browser Time by Trend and % Change. The client browser time averages are displayed for 1, 5, and 15 minute intervals.
The time the browser takes to display the page by subtracting the time the page is fully rendered from the time the page starts loading in the browser. The bulk of this time would be spent in Ajax calls to the server as well as executing Javascripts that are local to the currently viewed page.
The key notion to remember between the 1, 5 and 15 minute averages is the fact that these numbers are averages collected over time. This means that a high number for the 1 minute average is less significant than a high average in the 5 and 15 minute ranges, because it may just be a “spike” and may resolve itself soon enough.
The Client Browser Time is collected at the browser and sent back to your ServiceNow instance. Perspectium reads this value and generates a Medium Priority Alert when the Client Browser Time exceeds 60,000 ms or 1 minute, for any of the 1, 5, and 15 minute averaged times.
No valid Data Center license found
Please go to Atlassian Marketplace to purchase or evaluate Refined Toolkit for Confluence Data Center.Please read this document to get more information about the newly released Data Center version.
You can view the Client Network Time by Trend and % Change. The client network time averages are displayed for 1, 5, and 15 minute intervals.
The time the network takes to process the request by subtracting the time of the user's request from the time the page starts loading in the browser, and then subtracting the server processing time. Basically, this measures the time spent in the network after your page leaves the server but before it reaches your browser.
No valid Data Center license found
Please go to Atlassian Marketplace to purchase or evaluate Refined Toolkit for Confluence Data Center.Please read this document to get more information about the newly released Data Center version.
You can view the Server Response Time by Trend and % Change. The server response time averages are displayed for 1, 5, and 15 minute intervals.
This is the time the server takes to process the transaction. During this time, the ServiceNow Jelly rendering engine constructs the form (or fetches it from the cache) and merges in the data from the database. If there are any server side Javascripts defined in the path of constructing the response dynamically, the time also includes execution of these scripts.
No valid Data Center license found
Please go to Atlassian Marketplace to purchase or evaluate Refined Toolkit for Confluence Data Center.Please read this document to get more information about the newly released Data Center version.
No valid Data Center license found
Please go to Atlassian Marketplace to purchase or evaluate Refined Toolkit for Confluence Data Center.Please read this document to get more information about the newly released Data Center version.
Next, you're ready to start using Observer!